 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
May 19, 2026Automating scientific discovery requires more than generating papers from ideas. Real research is iterative: hypotheses are challenged from multiple perspectives, experiments fail and inform the next attempt, and lessons accumulate across cycles. Existing autonomous research systems often model this process as a linear pipeline: they rely on single-agent reasoning, stop when execution fails, and do not carry experience across runs. We present AutoResearchClaw, a multi-agent autonomous research pipeline built on five mechanisms: structured multi-agent debate for hypothesis generation and result analysis, a self-healing executor with a \textsc{Pivot}/\textsc{Refine} decision loop that transforms failures into information, verifiable result reporting that prevents fabricated numbers and hallucinated citations, human-in-the-loop collaboration with seven intervention modes spanning full autonomy to step-by-step oversight, and cross-run evolution that converts past mistakes into future safeguards. On ARC-Bench, a 25-topic experiment-stage benchmark, AutoResearchClaw outperforms AI Scientist v2 by 54.7%. A human-in-the-loop ablation across seven intervention modes reveals that precise, targeted collaboration at high-leverage decision points consistently outperforms both full autonomy and exhaustive step-by-step oversight. We position AutoResearchClaw as a research amplifier that augments rather than replaces human scientific judgment. Code is available at https://github.com/aiming-lab/AutoResearchClaw.
ClawForge: Generating Executable Interactive Benchmarks for Command-Line Agents
May 13, 2026Interactive agent benchmarks face a tension between scalable construction and realistic workflow evaluation. Hand-authored tasks are expensive to extend and revise, while static prompt evaluation misses failures that only appear when agents operate over persistent state. Existing interactive benchmarks have advanced agent evaluation significantly, but most initialize tasks from clean state and do not systematically test how agents handle pre-existing partial, stale, or conflicting artifacts. We present \textbf{ClawForge}, a generator-backed benchmark framework for executable command-line workflows under state conflict. The framework compiles scenario templates, grounded slots, initialized state, reference trajectories, and validators into reproducible task specifications, and evaluates agents step by step over persistent workflow surfaces using normalized end state and observable side effects rather than exact trajectory matching. We instantiate this framework as the ClawForge-Bench (17 scenarios, 6 ability categories). Results across seven frontier models show that the best model reaches only 45.3% strict accuracy, wrong-state replacement remains below 17\% for all models, and the widest model separation (17% to 90%) is driven by whether agents inspect existing state before acting. Partial-credit and step-efficiency analyses further reveal that many failures are near-miss closures rather than early breakdowns, and that models exhibit qualitatively different failure styles under state conflict.
ClawArena: Benchmarking AI Agents in Evolving Information Environments
Apr 05, 2026AI agents deployed as persistent assistants must maintain correct beliefs as their information environment evolves. In practice, evidence is scattered across heterogeneous sources that often contradict one another, new information can invalidate earlier conclusions, and user preferences surface through corrections rather than explicit instructions. Existing benchmarks largely assume static, single-authority settings and do not evaluate whether agents can keep up with this complexity. We introduce ClawArena, a benchmark for evaluating AI agents in evolving information environments. Each scenario maintains a complete hidden ground truth while exposing the agent only to noisy, partial, and sometimes contradictory traces across multi-channel sessions, workspace files, and staged updates. Evaluation is organized around three coupled challenges: multi-source conflict reasoning, dynamic belief revision, and implicit personalization, whose interactions yield a 14-category question taxonomy. Two question formats, multi-choice (set-selection) and shell-based executable checks, test both reasoning and workspace grounding. The current release contains 64 scenarios across 8 professional domains, totaling 1{,}879 evaluation rounds and 365 dynamic updates. Experiments on five agent frameworks and five language models show that both model capability (15.4% range) and framework design (9.2%) substantially affect performance, that self-evolving skill frameworks can partially close model-capability gaps, and that belief revision difficulty is determined by update design strategy rather than the mere presence of updates. Code is available at https://github.com/aiming-lab/ClawArena.
MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
Mar 17, 2026Large language model (LLM) agents are increasingly used for complex tasks, yet deployed agents often remain static, failing to adapt as user needs evolve. This creates a tension between the need for continuous service and the necessity of updating capabilities to match shifting task distributions. On platforms like OpenClaw, which handle diverse workloads across 20+ channels, existing methods either store raw trajectories without distilling knowledge, maintain static skill libraries, or require disruptive downtime for retraining. We present MetaClaw, a continual meta-learning framework that jointly evolves a base LLM policy and a library of reusable behavioral skills. MetaClaw employs two complementary mechanisms. Skill-driven fast adaptation analyzes failure trajectories via an LLM evolver to synthesize new skills, enabling immediate improvement with zero downtime. Opportunistic policy optimization performs gradient-based updates via cloud LoRA fine-tuning and Reinforcement Learning with a Process Reward Model (RL-PRM). This is triggered during user-inactive windows by the Opportunistic Meta-Learning Scheduler (OMLS), which monitors system inactivity and calendar data. These mechanisms are mutually reinforcing: a refined policy generates better trajectories for skill synthesis, while richer skills provide higher-quality data for policy optimization. To prevent data contamination, a versioning mechanism separates support and query data. Built on a proxy-based architecture, MetaClaw scales to production-size LLMs without local GPUs. Experiments on MetaClaw-Bench and AutoResearchClaw show that skill-driven adaptation improves accuracy by up to 32% relative. The full pipeline advances Kimi-K2.5 accuracy from 21.4% to 40.6% and increases composite robustness by 18.3%. Code is available at https://github.com/aiming-lab/MetaClaw.
From EduVisBench to EduVisAgent: A Benchmark and Multi-Agent Framework for Pedagogical Visualization
May 22, 2025
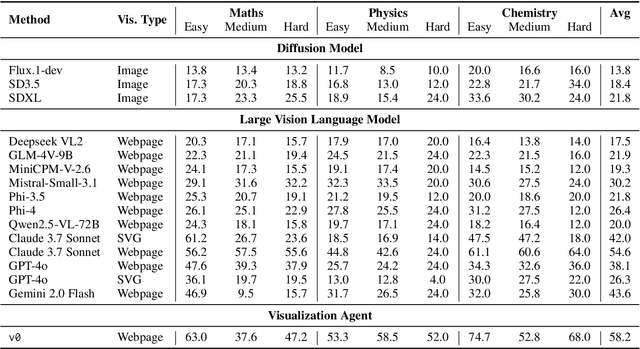
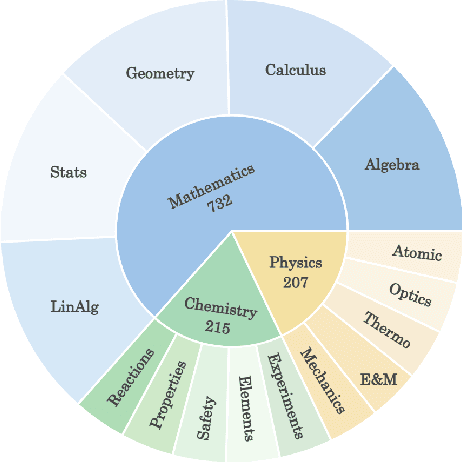
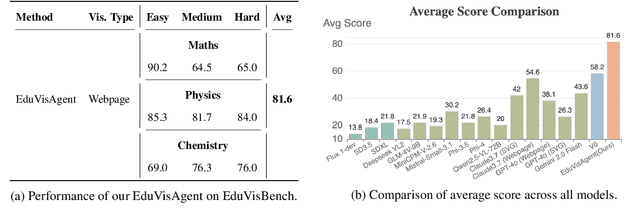
While foundation models (FMs), such as diffusion models and large vision-language models (LVLMs), have been widely applied in educational contexts, their ability to generate pedagogically effective visual explanations remains limited. Most existing approaches focus primarily on textual reasoning, overlooking the critical role of structured and interpretable visualizations in supporting conceptual understanding. To better assess the visual reasoning capabilities of FMs in educational settings, we introduce EduVisBench, a multi-domain, multi-level benchmark. EduVisBench features diverse STEM problem sets requiring visually grounded solutions, along with a fine-grained evaluation rubric informed by pedagogical theory. Our empirical analysis reveals that existing models frequently struggle with the inherent challenge of decomposing complex reasoning and translating it into visual representations aligned with human cognitive processes. To address these limitations, we propose EduVisAgent, a multi-agent collaborative framework that coordinates specialized agents for instructional planning, reasoning decomposition, metacognitive prompting, and visualization design. Experimental results show that EduVisAgent substantially outperforms all baselines, achieving a 40.2% improvement and delivering more educationally aligned visualizations. EduVisBench and EduVisAgent are available at https://github.com/aiming-lab/EduVisBench and https://github.com/aiming-lab/EduVisAgent.
MJ-VIDEO: Fine-Grained Benchmarking and Rewarding Video Preferences in Video Generation
Feb 03, 2025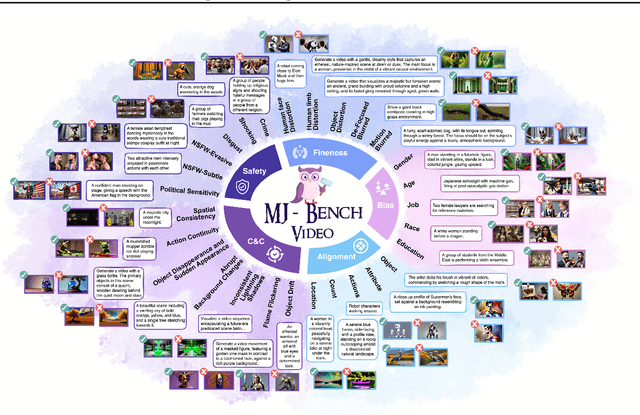
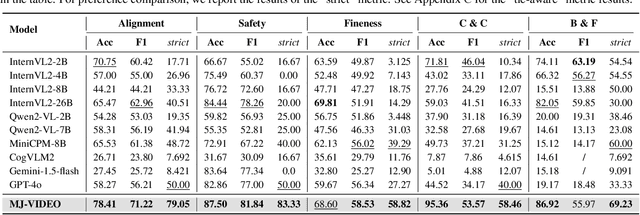
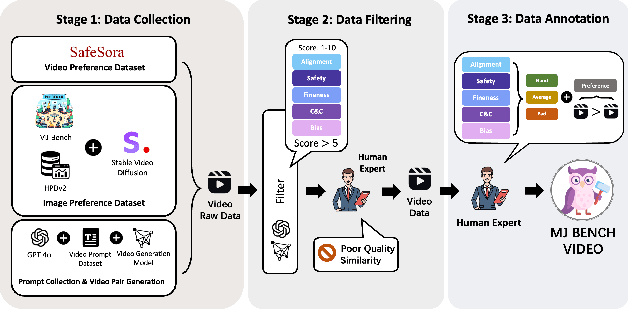
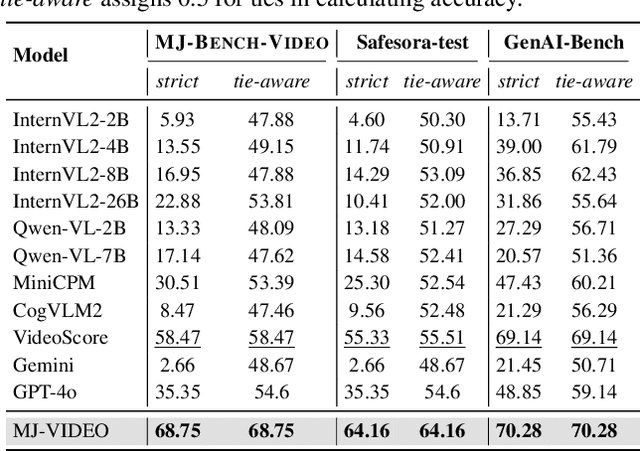
Recent advancements in video generation have significantly improved the ability to synthesize videos from text instructions. However, existing models still struggle with key challenges such as instruction misalignment, content hallucination, safety concerns, and bias. Addressing these limitations, we introduce MJ-BENCH-VIDEO, a large-scale video preference benchmark designed to evaluate video generation across five critical aspects: Alignment, Safety, Fineness, Coherence & Consistency, and Bias & Fairness. This benchmark incorporates 28 fine-grained criteria to provide a comprehensive evaluation of video preference. Building upon this dataset, we propose MJ-VIDEO, a Mixture-of-Experts (MoE)-based video reward model designed to deliver fine-grained reward. MJ-VIDEO can dynamically select relevant experts to accurately judge the preference based on the input text-video pair. This architecture enables more precise and adaptable preference judgments. Through extensive benchmarking on MJ-BENCH-VIDEO, we analyze the limitations of existing video reward models and demonstrate the superior performance of MJ-VIDEO in video preference assessment, achieving 17.58% and 15.87% improvements in overall and fine-grained preference judgments, respectively. Additionally, introducing MJ-VIDEO for preference tuning in video generation enhances the alignment performance.